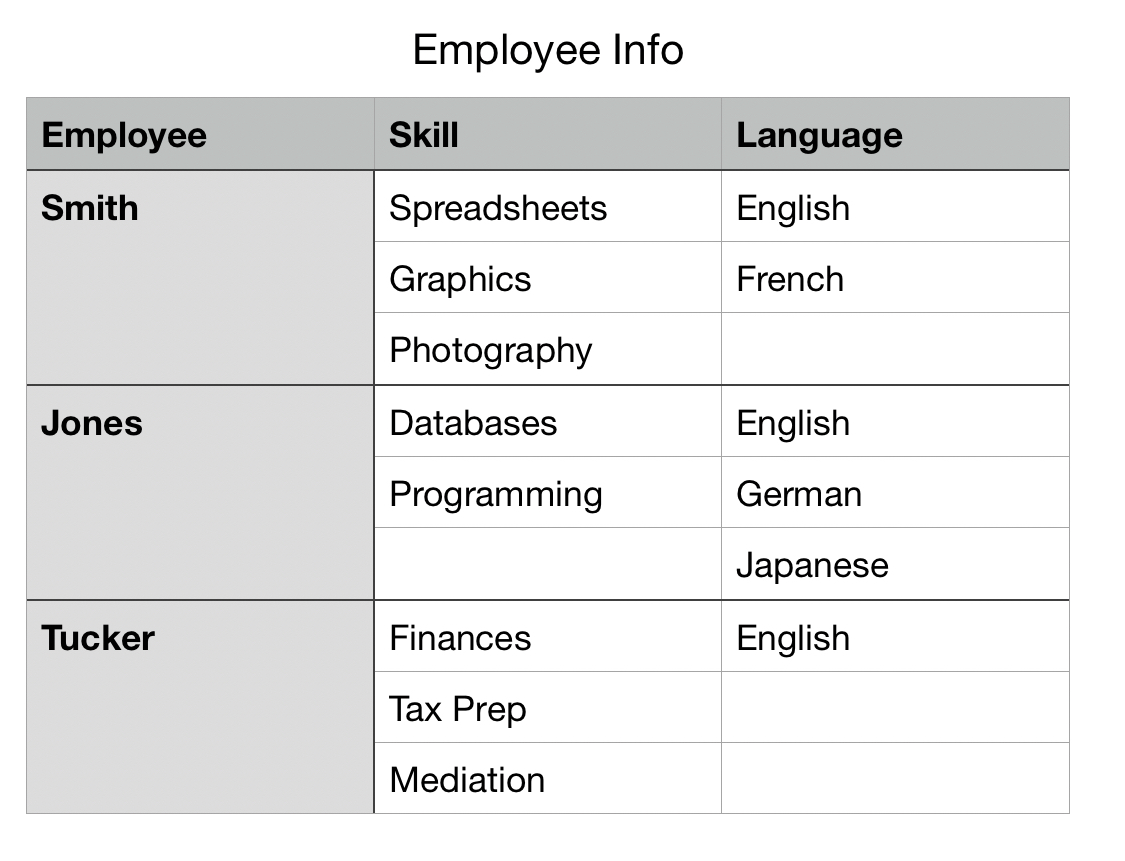
I’ve seen this design again and again, but not in relational databases. I usually see it in spreadsheets. I would be completely unsurprised to see a three column Excel sheet with Employee, Skill, and Language headers. (https://kerricklong.com/tmp/demo-4nf-need.jpg) The spreadsheet designer’s intuition is that Skill and Language are lists, and Employee is a section header. Smith might have a few rows with his languages and skills listed, one per cell, in arbitrary top-to-bottom order and with no consideration for how language and skill in a row relate to each other—only to Smith. The Employee column has a single merged cell for Smith, a number of rows tall it needs to be to contain the largest of his lists. When migrating this from a spreadsheet to a database, you lose merged cells as a feature and can no longer rely on order—so you copy the value Smith to each cell that had been merged.
{kind=link}
Perhaps TFA could explain what happened to math between 1977 and 2024. Because the meaning of "atomic" didn’t change, nor did the meaning of 1NF. The author pretends to explain 4NF, but never actually begins. He calls himself an "historian", which he might be. But he betrays very little knowledge of the relational model.
Repeating fields, which he proclaims as some kind of innovation, violate 1NF. They’re not atomic. Maybe the easiest way to understand it is that the list of languages can’t be used in SQL. If one teacher speaks Italian and French, SQL won’t find WHERE LANGUAGE = ‘FRENCH’. Nor will SQL join two teachers on that column.
SQL doesn’t recognize repeating fields in a column because it already has a way to represent them: as rows. That a teacher speaks two languages is not one fact, but two; not surprisingly, those two facts appear in two rows. ‘Twas true in in 1977. ‘Tis true today. Thus ‘twill ever be.
>20 years ago, when I started with databases, I found natural to map a user object in my software with a unique 'user' table with many columns. (Excel style)
It's only when I discovered how things were implemented and the required space and combinatorial complexity that the 4NF started to make sense.
I think the natural 'naive' approach is to have many columns with redundant information inside.
At some point, with more experience, we see how this system is harder to maintain (burden on the code logic) and how much space is wasted. I discovered 4NF (without giving it a name) by myself to solve those issues.
The problem is that we teach 4NF to people that never implemented code with databases and had to solve the problems it generates if you only have multiple columns. So the examples seems artificial.
When for the first time I saw 4NF in my lectures, it was easy as I knew all the issues without.
It was and is still common to have non experts design databases. And in many cases, normal form doesn't make sense. Tables with hundreds or thousands of columns are commonly the best solution.
What is rarely stressed about NF is that update logic must exist someplace and if you don't express the update rules in a database schema, it must be in the application code. Subtle errors are more likely in that case.
In the 1990s I was a certified Novell networking instructor. Every month their database mysteriously delist me. The problem was never found but would have been prevented if their db was in normal form. (Instead I was given the VP of education's direct phone number and he kept my records on his desk. As soon as I saw that I was delist, I would call him and he had someone reenter my data.)
Adding fields to tables and trying to update all the application code seems cheaper than redesigning the schema. At first. Later, you just need to normalize tables that have evolved "organically", so teaching the procedures for that is reasonable even in 2024.
"The existence of the theory implies that the “composed” design somehow arises, naively(?) or naturally."
Given how many first timers come up with really weird schema designs, I'm not necessarily surprised, although I agree presenting it as perhaps a default-but-wrong approach doesn't help much.
Performance characteristics of the underlying hardware dictate the software abstractions that make sense. In today's machines, we still have differential cost for sequential, aligned, rightly sized block io operations vs random io operations of random sizes. And we have a hierarchy of storages with different latency, performance and costs – cpu caches, ram – and ram, ssd, spinning disks – and these via local attached vs in disaggregated and distributed clusters. So, if you want absolutely optimal performance, you still have to care about your column sizes and order of columns in your records and how your records are keyed and how your tables involved in join operations are organized and what kinds of new queries are likely in your application. This matters for both very small scale (embedded devices) and very large scale systems. For mid-scale systems with plenty of latency and cost margins, it matters a lot less than it used. Hence, we have the emergence of nosql in the last decade and distributed sql in this decade.
There are several issues with this:
1. 4NF is dependent on context. This context is described as dependencies.
In the example of employees, skills and languages the design with two separate "link tables" employee_skills and employee_language is not obvious at all without specifying requirements _first_. If there is a requirement that an employee skill depends on the language (ie. an employee can type in a particular language only) - the design with a single 3 attributes table is the right one.
2. Multivalued attributes discussion is missing several important aspects for example referential integrity. It is not at all obvious what should happen when a language is deleted from languages table. Once you start adding rules and language to specify referential integrity for multivalued attributes you very quickly end up with... splitting multivalued attributes into separate relations.
A possible clue is that the weird composed form is, still, the only possible form in which you can actually get results out of your SQL database.
Perhaps people worked backwards from sample query results, reasoning that an output that looks like that should come from a table that looks like that. Of course that begs the question of why that ever seemed like a sensible format for output, but apparently the SQL establishment has never seen fit to change it, so either the SQL people are all idiots or there's some advantage to that form.
(Yes, I know there is an obsolete meaning of that phrase still recorded in some dictionaries, but I prefer to use live English)
When I learned quantum mechanics as part of a Chemistry BSc, it was broken down so as to be easier to digest. It made it much fucking harder for me. When I did it as a Phsyicist, they just laid out the math and it was super straightforward. I think back when they came up with 4NF, everyone was still trying to figure out what the fuck they were talking about, and so explanations were needlessly complicated.
Anyway, now with non-relational databases, 4NF can slow you down.
Excellent article. 1NF is part of the problem as the article mentions.
I'm seen some articles say that atomic in 1NF means you cannot have things that can be decomposed. All that matters is that you can perform the relational algebra on the table and get a sensible result.
To the why of presenting normalisation from those wacky forms, I think that also comes from data ingestion. You'll get a list of attributes for an employee from their CV and might naively just load that 'as is' into a table.
Database normalization: https://en.wikipedia.org/wiki/Database_normalization
The origin of classic explanation probably comes from people attempting to computerize paper forms. The school would have profiles for each teacher, probably a series of pages in a manila folder stored in a filing cabinet, that was filled out by hand/a typewriter. A space for the name. A series of blanks to be filled in with a list of skills (that maxes out at however many blanks they could put on the page). A series of blanks for languages. Woe is the teacher who knows more languages than the available blanks that are on the form!
People still create tables today (yes, even in 2024) like (teacher, skill, language) as the row definition. Someone looks at the list of information they are collecting, conclude that the only axis they need to query on is the teacher, and make wide tables with many columns with disjoint purposes, that are then difficult to query and are inflexible.
Consider a library card catalog and the Dewey Decimal Classification system. The cards are arranged in the drawers by the topics standardized in the DDC. It looks like the major axis is the DDC numbering and their associated topics. While a card catalog lets you search for specific books if you know the topic and the author, it can not easily tell you all the books by the same author, or the list of topics that an author covers. Or find all the books that multiple authors have written together. But if one was to take the card catalog as it existed and computerize it, the naïve implementation would look like the unnormalized or lower normalization forms. The explanation of the progression of increasing normalization tells you how to incrementally achieve normalization given a data schema that was heavily influenced by the limitations of physical reality, such that a card catalog is, into a system that does not have those constraints.
The example of storing the skills and language as a list in a column is grossly inefficient in usage (ignoring the inefficiencies in storage and performance) and ignores that the "list" in 4NF is actually the result set, the set of rows returned. I suppose it could help one to think of the result set as horizontal columns (a list) rather than a vertical set of rows, but that's more of a side effect of the data presentation than the relational algebra underpinnings. Despite that databases like postgres let you query and index on expressions applied to a JSON-typed column, you end up with something more complex, with different methods of enforcing data hygiene at the row and the individual column level, because you've got sets of data in a single column, when the set is the defined by the rows. 4NF lets you answer way more questions about the data than you might initially anticipate. I've worked with a number of schemas that someone else created with no or little normalization that literally could not answer the desired questions. In this example, improper normalization results in finding out the skills of a teacher is easy, but finding out if the school is weak in any areas and what they should hire for is hard. But when the data is 4NF, you can answer questions easily in both directions without jumping through any data conversion hoops and you can have high confidence that the data remains hygienic.
What if the languages available do depend on what the lesson is about? That would require the composed form. Skipping it entirely is not the way to go.
You could start with decomposed and then compose it, I guess. I don't think either order is inherently easier to learn.
I agree that the wording of the normal forms, before getting to examples, is usually confusing.
Every time I read explanations of any database anything, it looks childishly simplistic to what I've done with C pointers and structs.
Basically it all exists because of storage devices:
- large transfer factors (spinning platter hard drive track access, flash erase blocks)
- latency (spinning platter track to track seek, and rotational latency)
Once you have fast random access, it's data structures and algorithms: forget the database cruft.
I think the typical presentation of 4NF makes more sense when you consider the ergonomics of data processing systems when relational modeling emerged. Predating computing, data processing was all centered around "records." Relational databases are often also described in terms of "records," relational modeling emerged out of an attempt to formalize data processing practices, the practitioners of the era were learning relational modeling from a data processing background, so it's no surprise that relational concepts are often presented "as opposed to" the way things were done in data processing.
In traditional data processing systems, a "record" was far more independent than we think of in a relational database. Records were hand-punched onto cards or keyed onto magnetic tape to be sorted, summarized, or whatever operation you cared about by a data processing machine. In this environment, joins were extremely expensive operations, often requiring that the operator feed the card stack over and over again (a rather literal O(n^2)). So, the "weird composed" schema is absolutely what you would do. And a lot of computer software was built around the exact same concepts, which made sense anyway as computers often continued to use sequential-access storage devices with similar (but less severe) problems around joins. This era famously persisted for a long time, with relational modeling as an academic concept well predating successful implementations of relational databases.
One could argue that all of the normal forms are pretty much "stop doing it the old sequential access (card-stack) way and use random access concepts (keys and joins) instead."
Of course that leaves the question of whether or not we should teach it that way... we don't tend to tell students about how memory is now random access, so perhaps by the same turn the historical approach isn't useful for teaching here. But it would undoubtedly be more effective if you give a little of the history.